Databricks: Pushing the frontier for data agents with Genie¶
Source: Pushing the Frontier for Data Agents with Genie by The Databricks AI Research Team (Databricks blog, published 2026-05-08).
Purpose: Local summary and figure archive for later adaptation; not a substitute for the canonical article or Databricks Genie product documentation.
Figures are stored under databricks-pushing-frontier-data-agents-genie/assets/ relative to this file. Attribution remains with Databricks; assets were downloaded from the article’s CDN for offline review.
Key takeaways (article)¶
- Genie is Databricks’ data agent for complex enterprise questions over structured assets (tables, dashboards, notebooks) and unstructured sources (workspace files, Google Drive, SharePoint).
- Data agents face challenges coding agents do not: massive cross-system discovery, ambiguous “source of truth” business knowledge, and no deterministic tests for open-ended analytical answers.
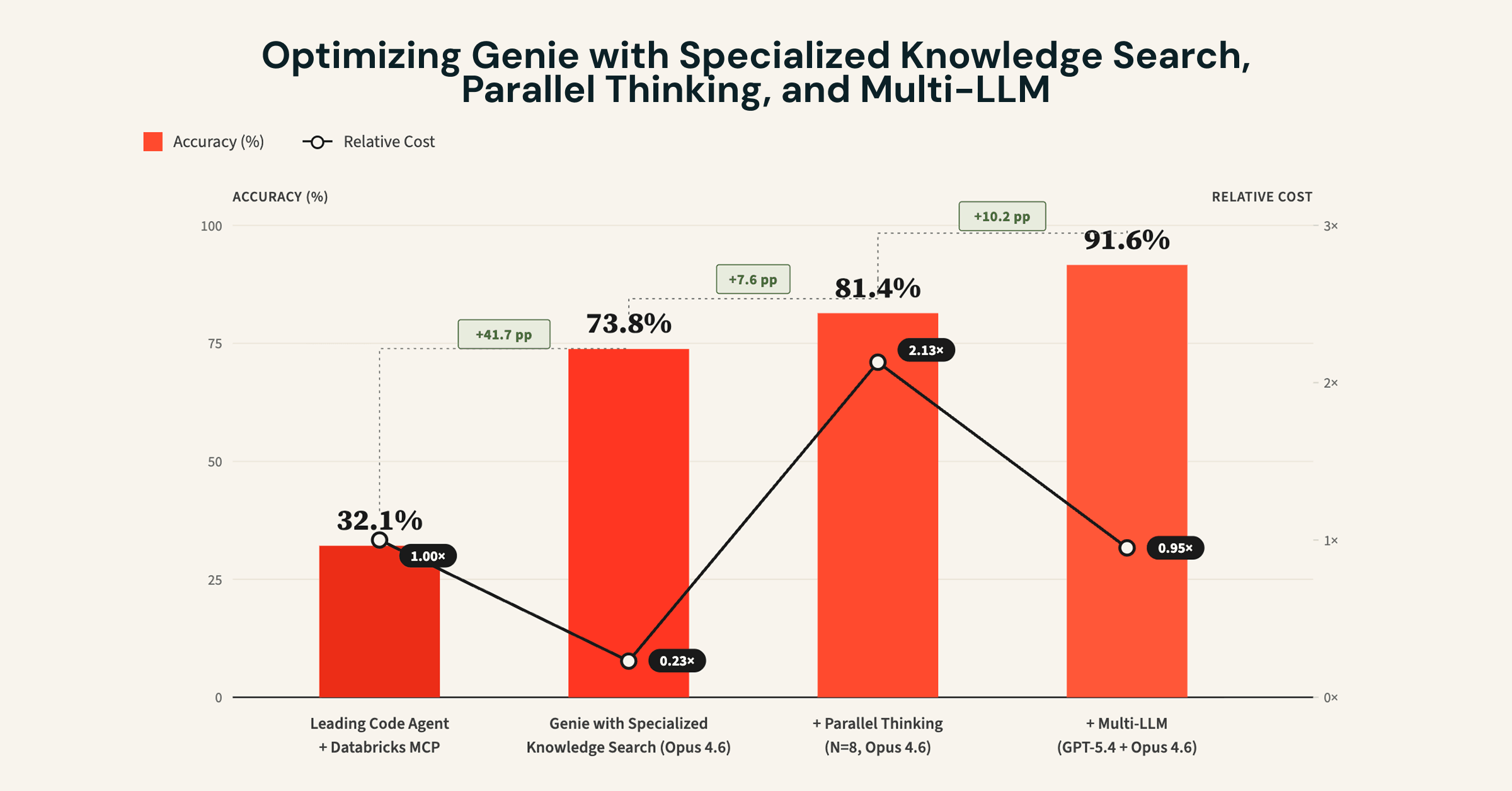
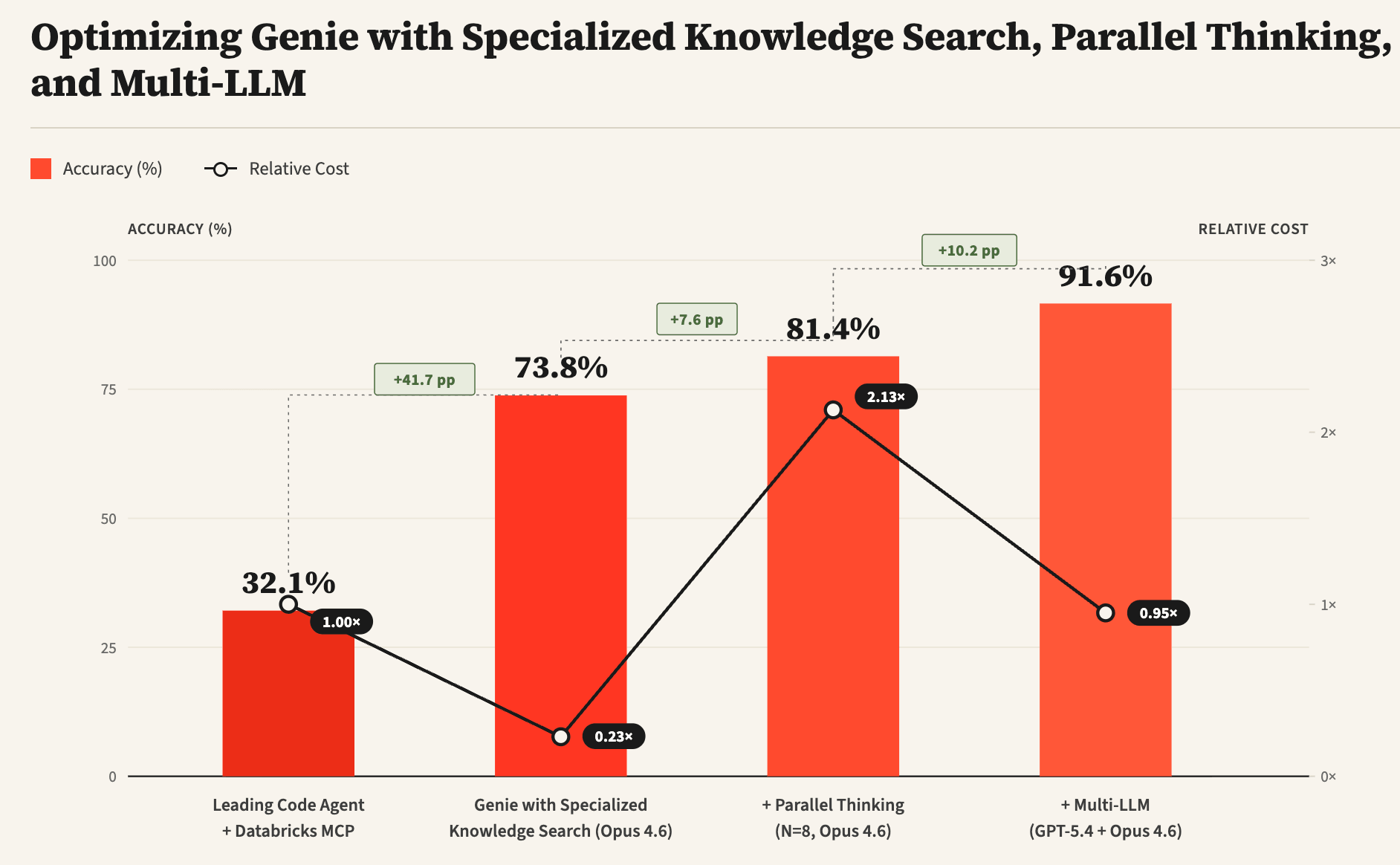
- Reported techniques: specialized knowledge search, parallel thinking, and multi-LLM sub-agent design with optimized prompts: raised internal benchmark accuracy from about 32% (leading coding agent baseline) to over 90% while reducing cost and latency.
- A representative trajectory combines parallel multi-agent discovery, investigation, self-correction, and verification when reconciling contradictory dashboards.
Introduction¶
Genie is Databricks’ state-of-the-art data agent for answering complex questions about enterprise data spanning structured and unstructured sources. The article describes unique data-agent challenges and techniques to address them: specialized knowledge search, parallel thinking, and multi-LLM designs. On an internal benchmark of real-world data analysis tasks, these techniques significantly improved Genie accuracy versus a leading coding agent (from 32% to over 90%) while reducing cost and latency.
Key challenges for data agents¶
Coding agents operate in relatively static, deterministic environments such as a disk file system. Data agents work in a dynamic lakehouse with semantic context across hundreds of thousands of tables, notebooks, dashboards, and documents.
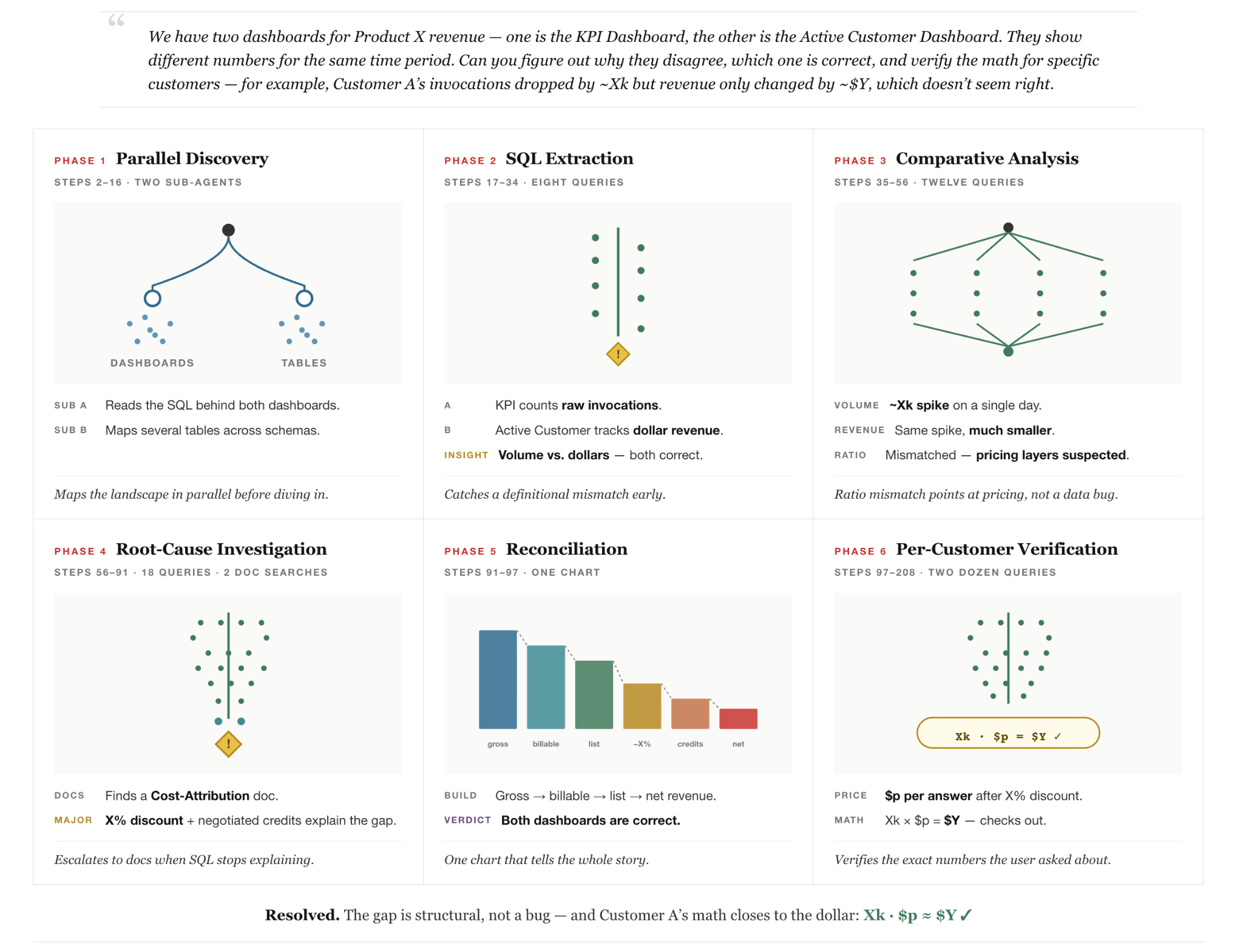
The article walks through an anonymized internal example: two enterprise dashboards report the same product’s revenue with contradictory spike dates. No single source holds the answer; resolving it requires cross-system discovery, reasoning about multi-day report setup, enterprise pricing and contract rates, and self-correction when intermediate calculations contradict initial assumptions. The agent proceeds through parallel multi-agent data discovery, data investigation, a self-correction loop, and verification.
Compared with coding agents, data agents face three distinctive challenges:
| Challenge | Why it matters |
|---|---|
| Scale of data discovery | Enterprise customers can have millions of structured and unstructured sources; conventional search breaks at that scale. |
| Determining “source of truth” business knowledge | Answers depend on metadata, documents, and messages that may be outdated, contradictory, or superseded. |
| Lack of verifiable tests | Unlike code with deterministic tests, the specification is only the user’s high-level question; some queries are unanswerable because data is incomplete. |
Key technical advances¶
Genie’s innovations relative to generic coding agents:
- Specialized knowledge search : semantic contextual data grounds asset-discovery sub-agents and improves search quality.
- Parallel thinking : sample multiple trajectories and aggregate findings for the final answer.
- Multi-LLM : different models for different sub-agents with optimized prompts to improve accuracy and latency.
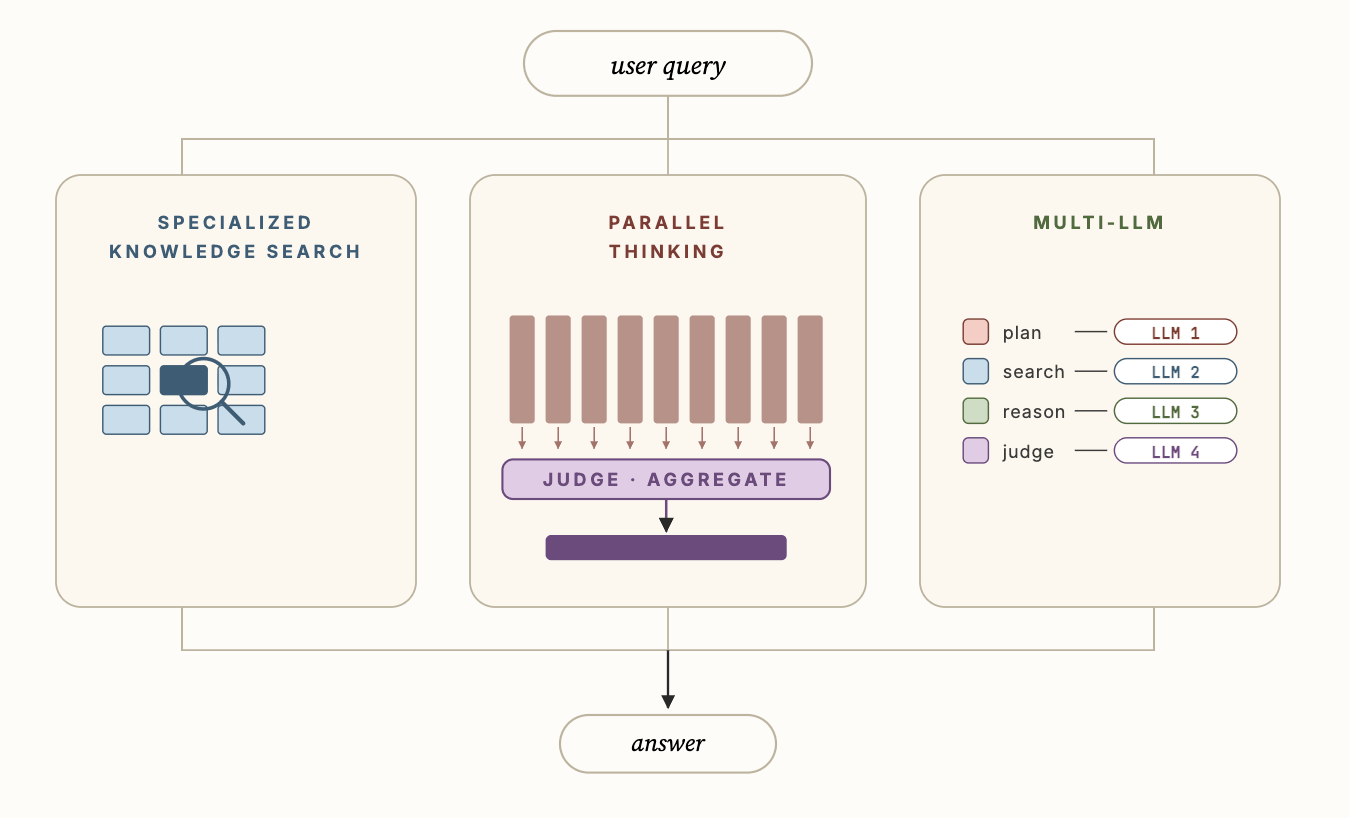
Specialized knowledge search¶
Genie derives rich semantic enterprise context from workspace tables, notebooks, dashboards, documents, and files, then builds search indices. It queries multiple indices in parallel with metadata signals to discover relevant assets. On table discovery benchmarks, specialized knowledge search improved table search performance by up to 40%.
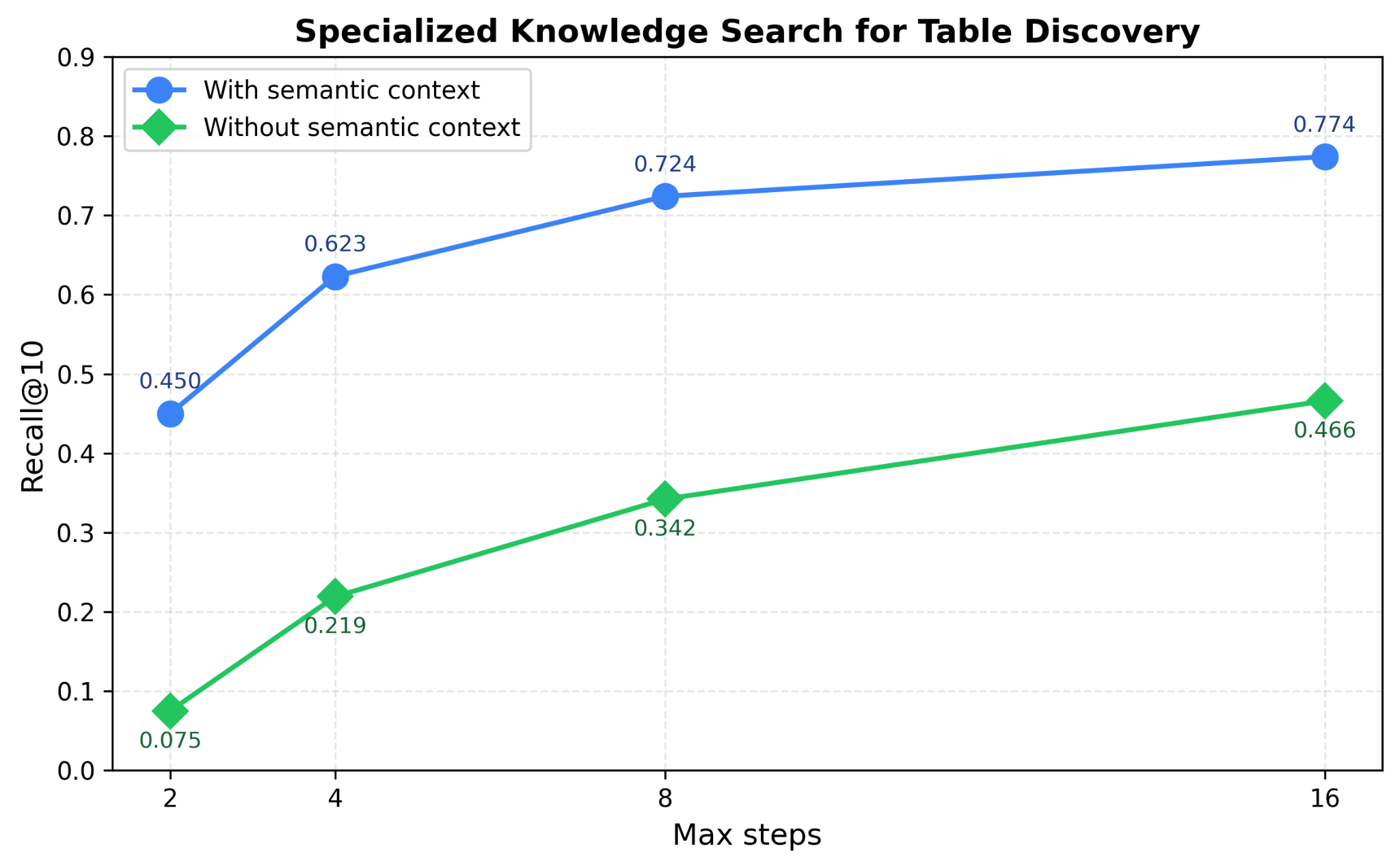
Parallel thinking¶
Open-ended data queries lack unit tests comparable to software engineering workflows. Without tests, agents struggle to know whether an answer is correct or needs refinement. Parallel thinking samples multiple trajectories and aggregates relevant information. The article reports higher answer accuracy with added latency and token cost; combining multi-LLM and further optimizations can reduce cost and latency (see Figure 1).
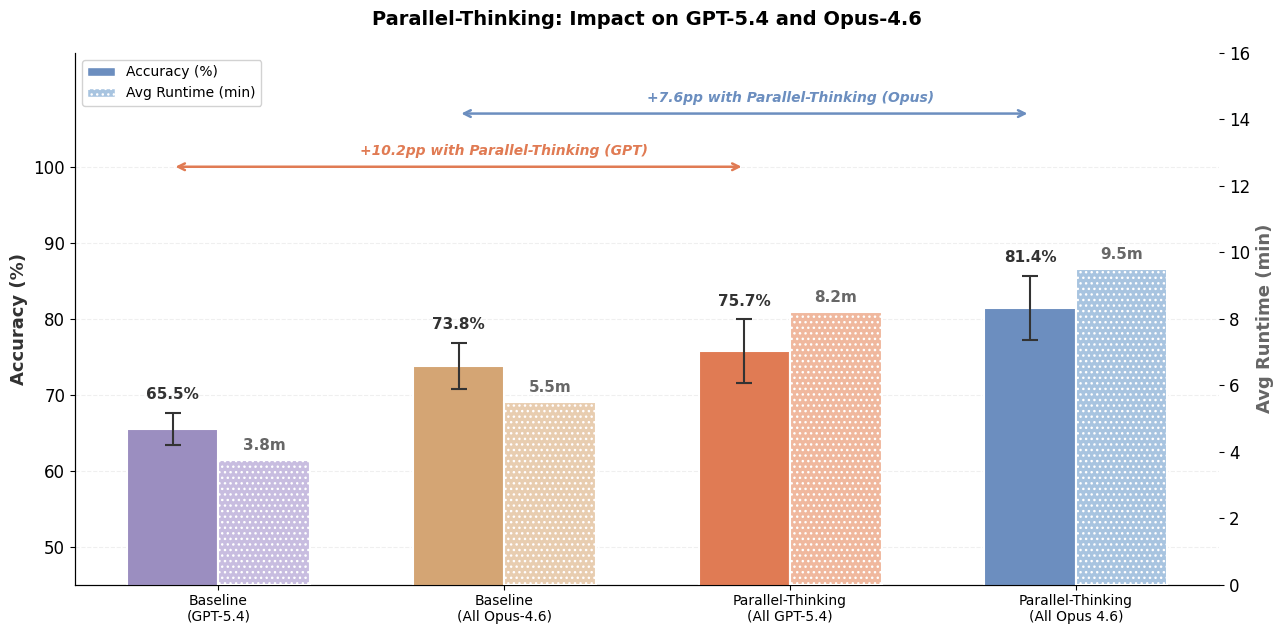
Multi-LLM¶
Different LLMs excel at complementary capabilities: planning, search sub-agents, code generation, and judging can each use a different model. On Databricks, teams can try frontier models (Opus, GPT, Gemini), open-source models, and custom-trained models. Latency and cost vary materially by model choice. Table search accuracy and cost can be further optimized with methods such as GEPA.
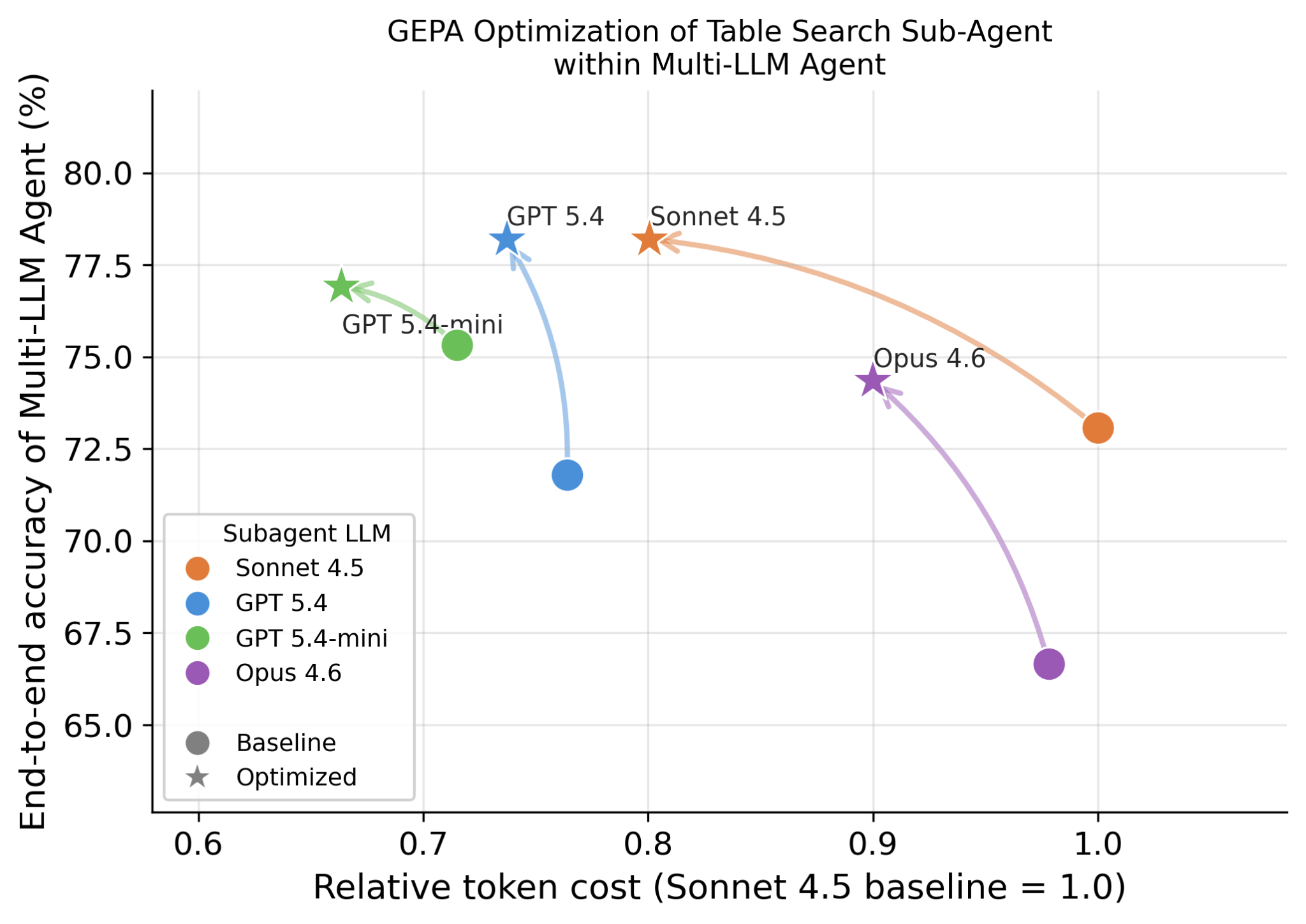
Conclusion¶
Coding and data analysis share conceptual similarities, but enterprise data systems are dynamic. Data agents must discover the right assets at scale, determine truth amid ambiguity, and write efficient queries and code. Specialized knowledge search, multi-LLM routing with optimized prompts (including GEPA), and parallel thinking materially outperform leading coding agents on the article’s benchmark tasks. Open research questions remain for state-of-the-art enterprise data agents.