LangChain: The runtime behind production deep agents¶
Source: The runtime behind production deep agents by Sydney Runkle and Vivek Trivedy (LangChain blog).
Purpose: Local summary and figure archive for later adaptation; not a substitute for the canonical article or LangSmith documentation.
Figures are stored under assets/ relative to this file. Attribution remains with LangChain; assets were downloaded from the article’s CDN for offline review.
Key takeaways (article)¶
- A strong harness (prompts, tools, skills, and the model loop) is necessary but not sufficient for production; a runtime underneath provides durable execution, memory, multi-tenancy, human oversight, and observability.
- Durable execution is foundational: checkpointed runs can pause, resume, retry, and survive process loss, deploys, and long waits for humans.
- Production agents benefit from open, model-agnostic infrastructure: MIT-licensed harness patterns, open protocols (MCP, A2A), and memory in operator-controlled storage (PostgreSQL by default in the article’s stack).
Harness versus runtime¶
The article separates what you build around the model from what keeps agents alive in production:
- Harness: domain prompts, tool wiring, skills, and the reason-act-observe loop.
- Runtime: queues, checkpointing, auth, streaming, tracing, sandboxes, schedulers, and integration endpoints.

Production requirements mapped to runtime capabilities¶
| Production requirement | Runtime capability |
|---|---|
| Reliability | Durable execution |
| Memory | Checkpoints (short-term), store (long-term) |
| Guardrails | Middleware |
| Multi-tenancy | Authentication, authorization, Agent Auth, RBAC |
| Human oversight | Human-in-the-loop (interrupt/resume) |
| Real-time interaction | Streaming, concurrency control (double-texting) |
| Observability | Tracing, time travel |
| Code execution | Sandboxes |
| Integrations | MCP, A2A, webhooks |
| Scheduled jobs | Cron |
In the article, “the runtime” refers to LangSmith Deployment and its Agent Server (assistants, threads, runs, memory, cron).
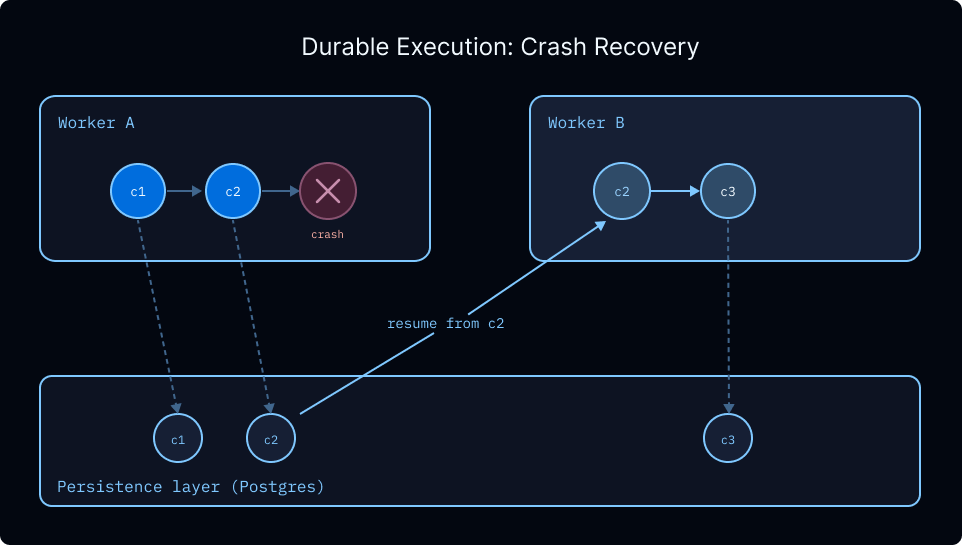
Durable execution¶
Agent loops can run for minutes or hours with many model and tool steps. Production needs:
- Surviving worker crashes without redoing completed work.
- Truly stopping while waiting for humans (freeing workers) and resuming later from the same logical point.
Mechanisms described include managed task queues, checkpointing keyed by thread_id, lease handoff on crash, configurable per-node retries, and super-step persistence (PostgreSQL by default).
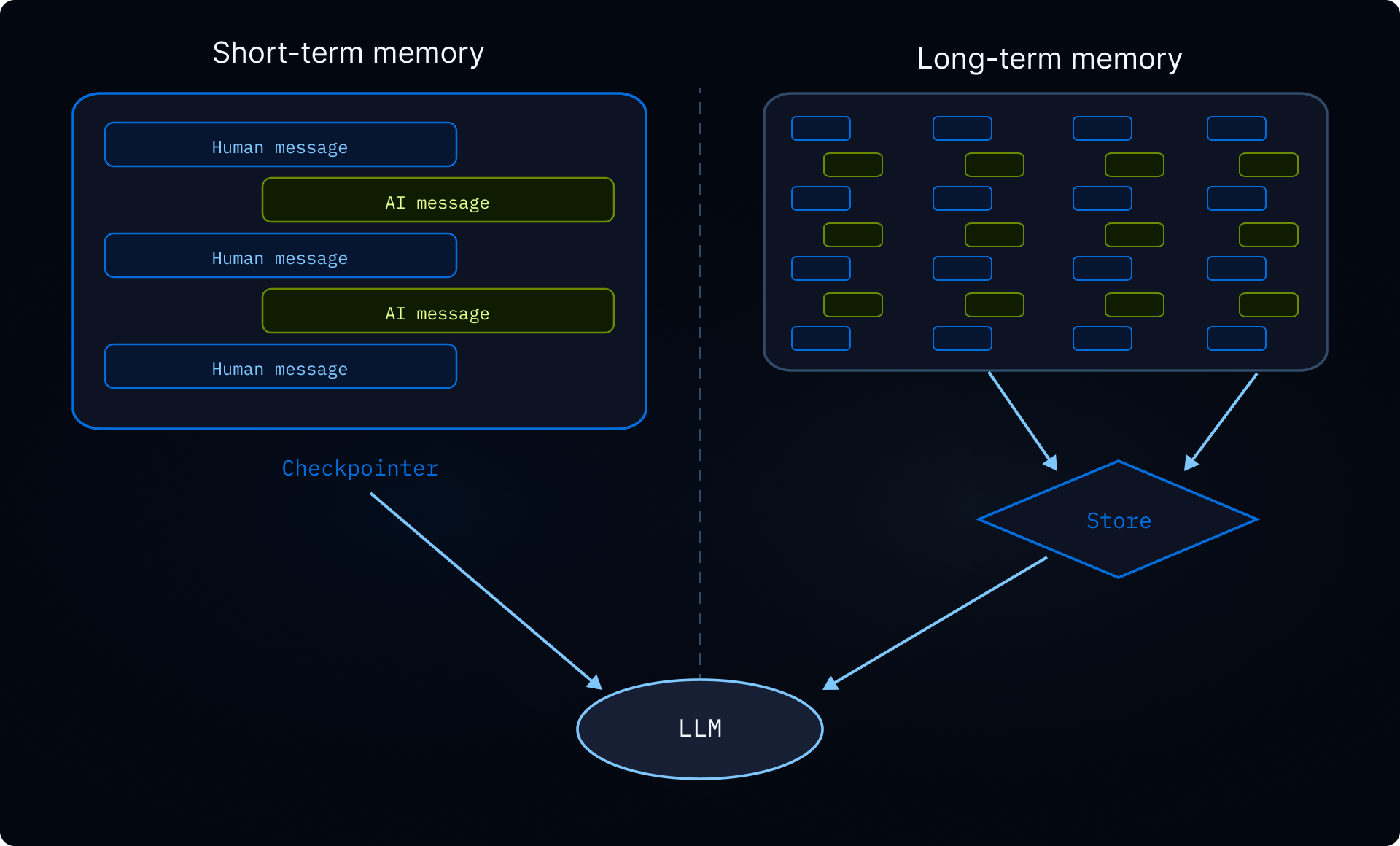
Memory¶
Short-term memory is thread-scoped checkpoint state: messages, tool calls, and intermediate graph state for one conversation.
Long-term memory uses a store (key-value with namespace tuples, semantic search optional) persisted across threads: for preferences, org conventions, or knowledge accumulated over time. The article stresses keeping this data in operator-controlled storage for migration and analysis.
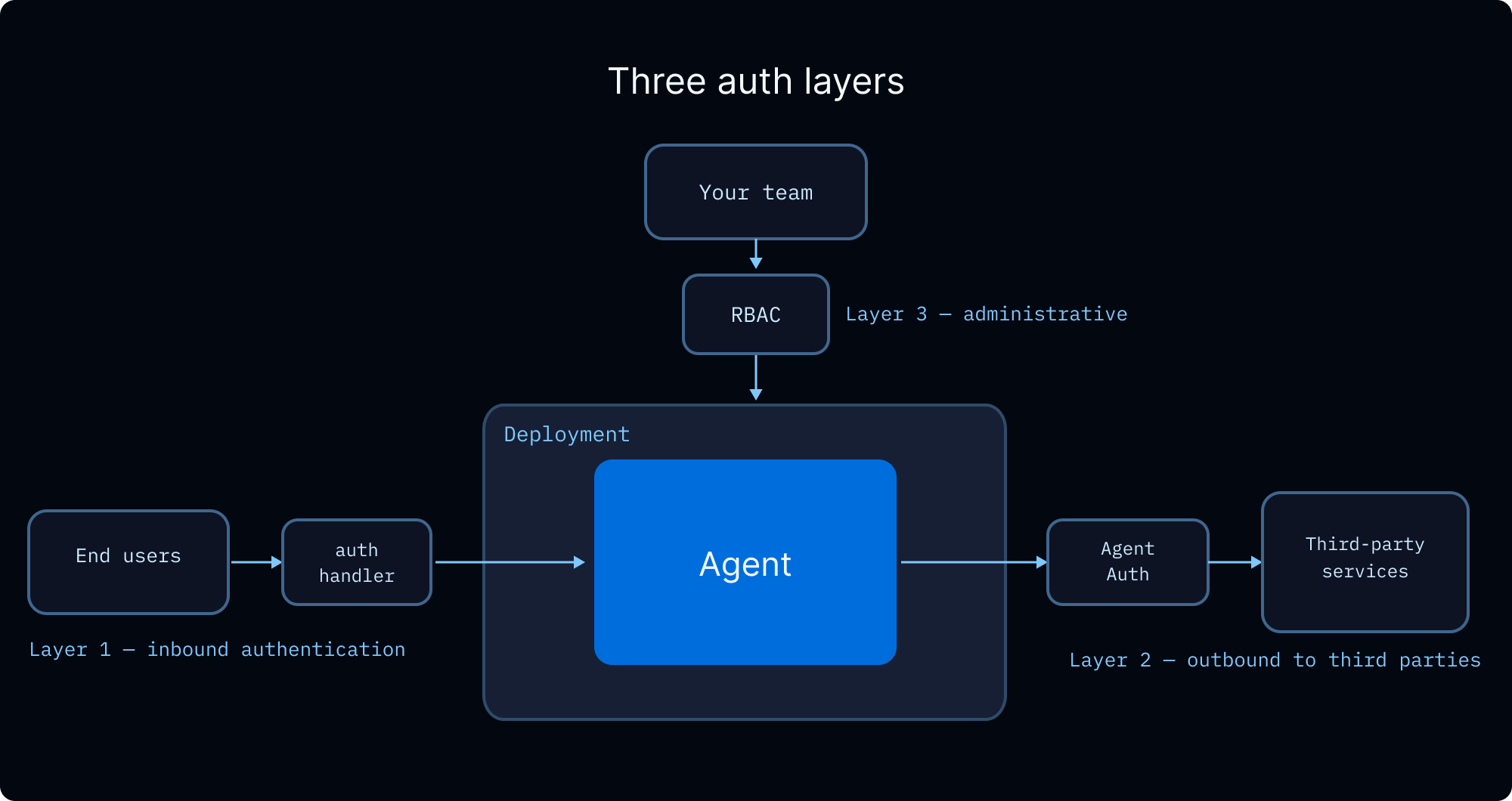
Multi-tenancy¶
Three composed layers:
- Isolation : custom auth middleware, resource tagging, and read filters so users only see their threads and memories.
- Acting on behalf of users : Agent Auth for OAuth and token refresh when agents call third-party APIs with user credentials.
- Operator control : RBAC for who can deploy, configure, view traces, or change policies.
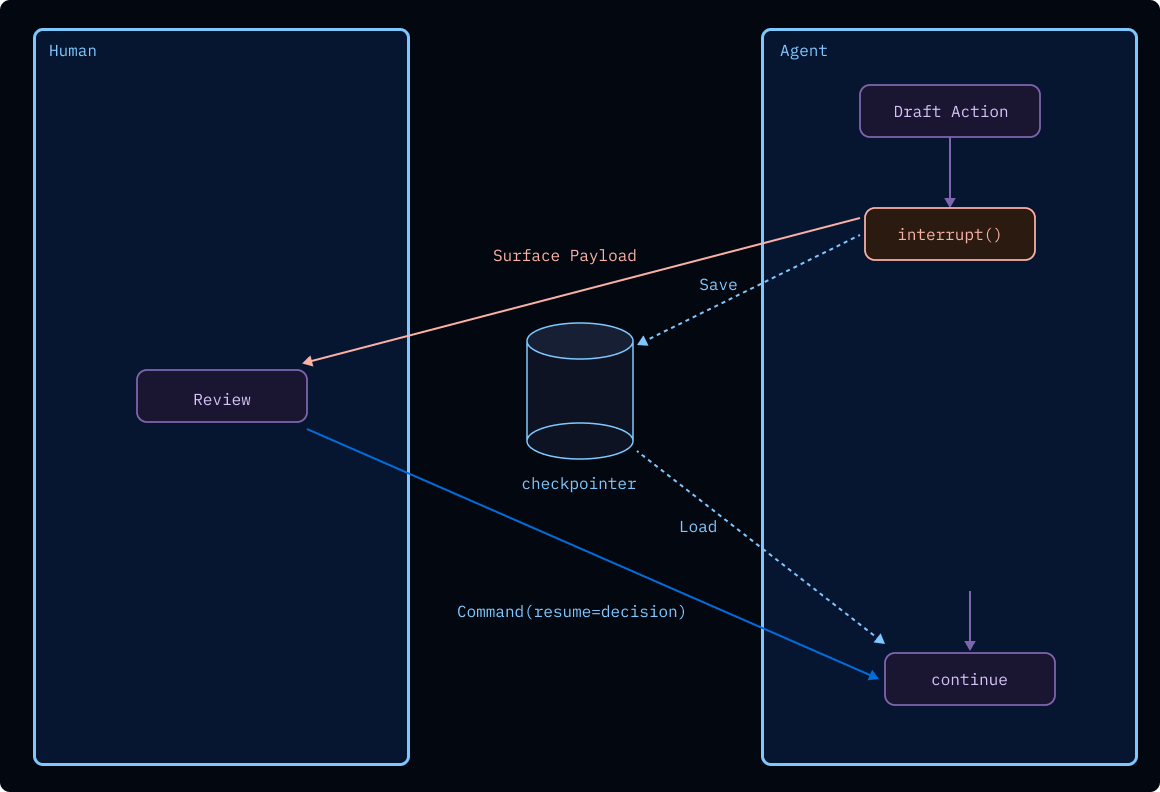
Human-in-the-loop (HITL)¶
Common patterns:
- Review consequential tool calls before execution (approve, edit, reject with rationale).
- Ask clarifying questions when judgment is required instead of guessing.
Primitives: interrupt() to pause and surface payload; Command(resume=...) to continue with arbitrary JSON-serializable responses. Checkpoints make waits indefinite without holding workers; parallel interrupts can be resumed together or individually.
Real-time interaction¶
Streaming¶
Partial output during long runs; modes include full snapshots, deltas, token streams, and custom events. Thread streaming can follow multiple runs on one thread; Last-Event-ID supports reconnect without gaps.
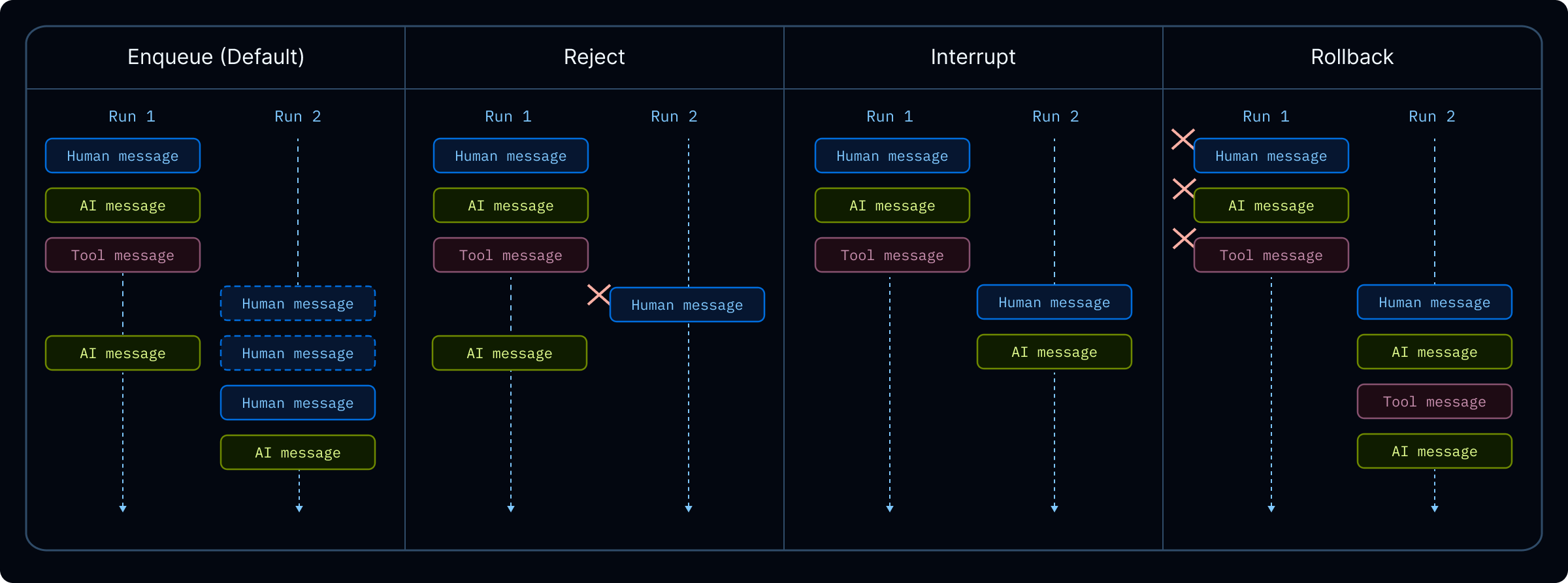
Double-texting¶
Policies when a new user message arrives while a run is active: enqueue (default), reject, interrupt (halt and continue from state), or rollback (discard in-flight work). Tradeoffs between snappy UX and state safety are explicit.
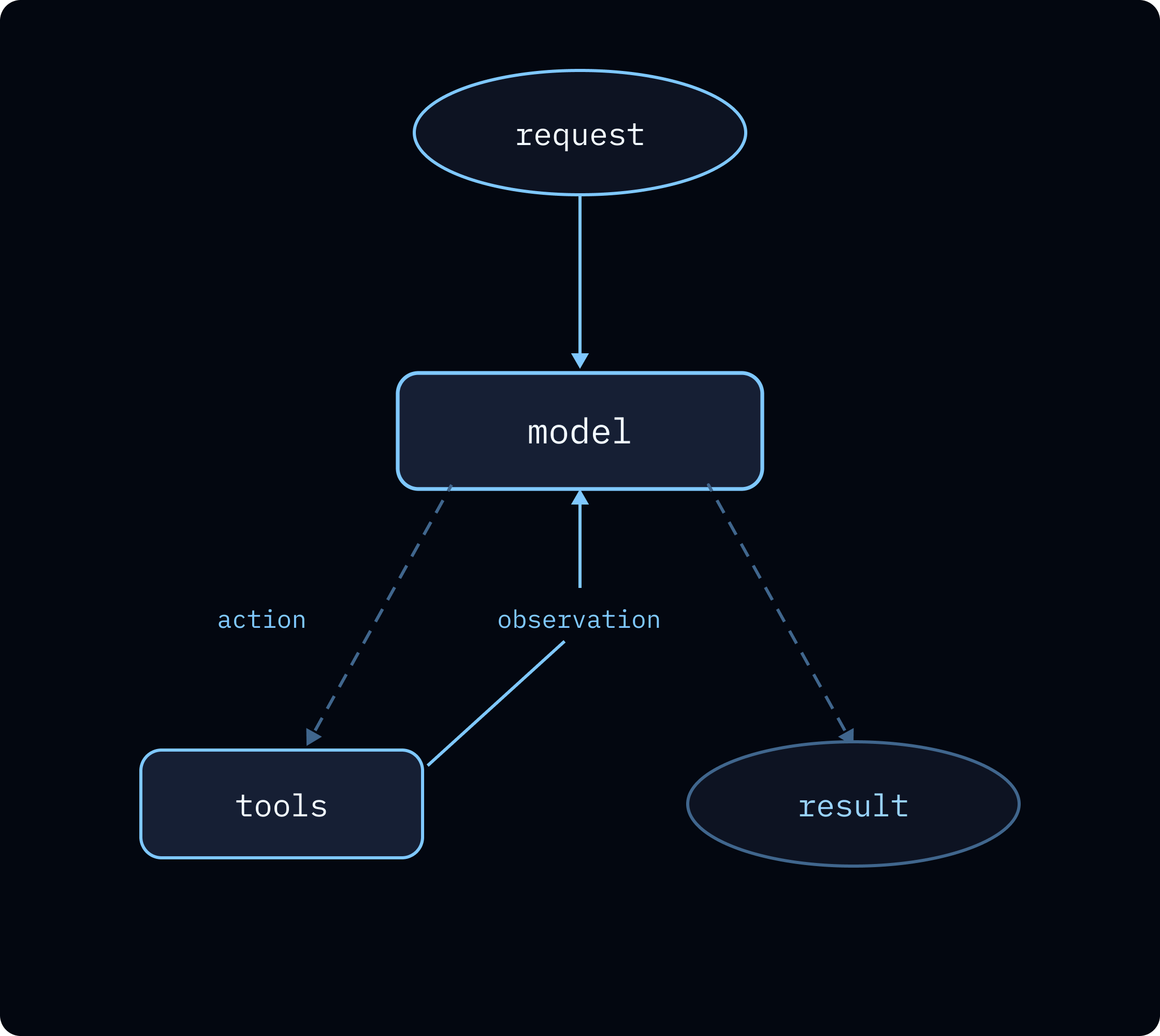
Guardrails (middleware)¶
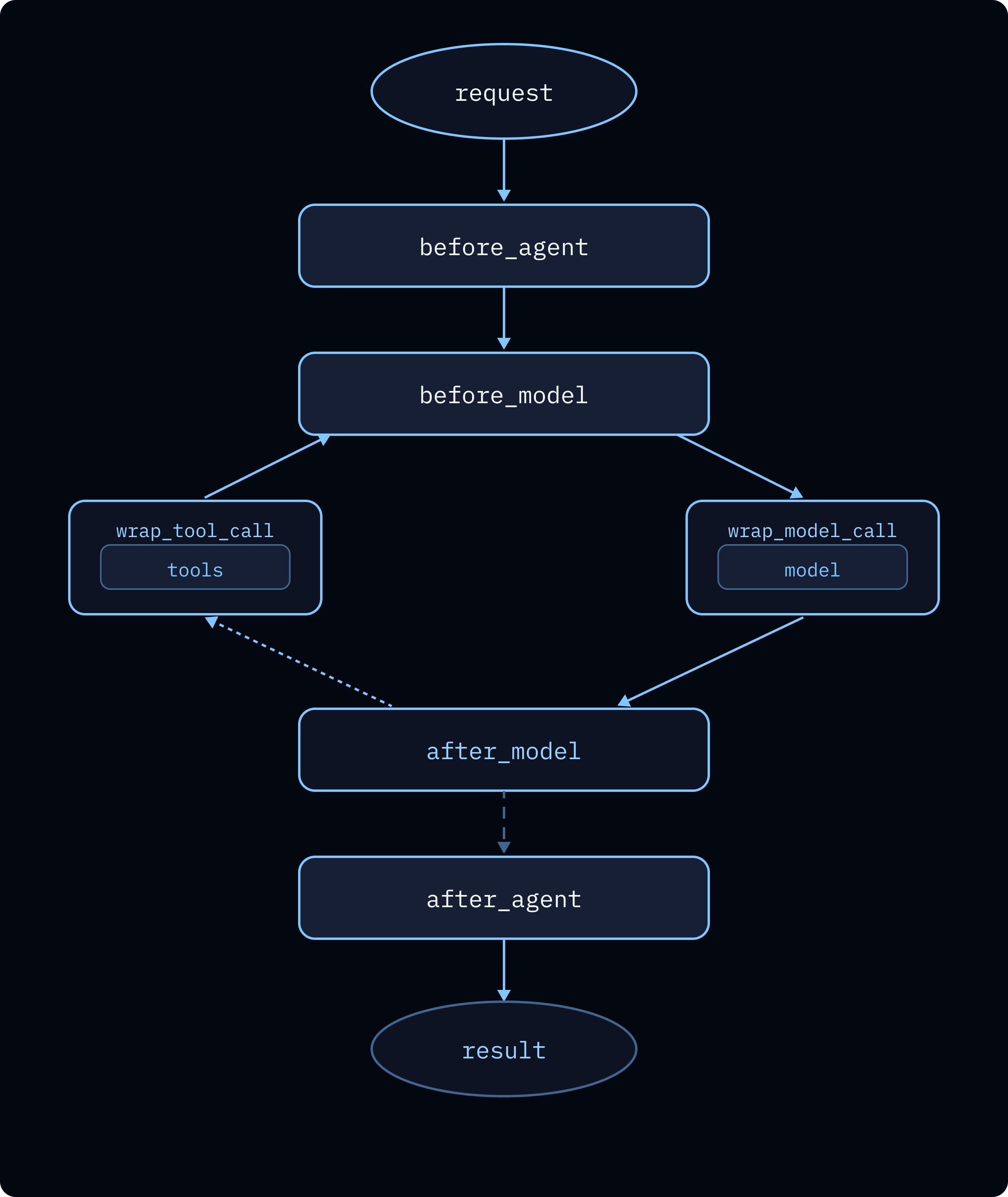
Policies belong in code at deterministic hooks (before_model, wrap_model_call, wrap_tool_call, after_model) for redaction, spend caps, moderation, retries, and fallbacks. The article lists built-in middleware examples and notes value when middleware wraps every interaction mode (streaming, HITL, retries, background runs).
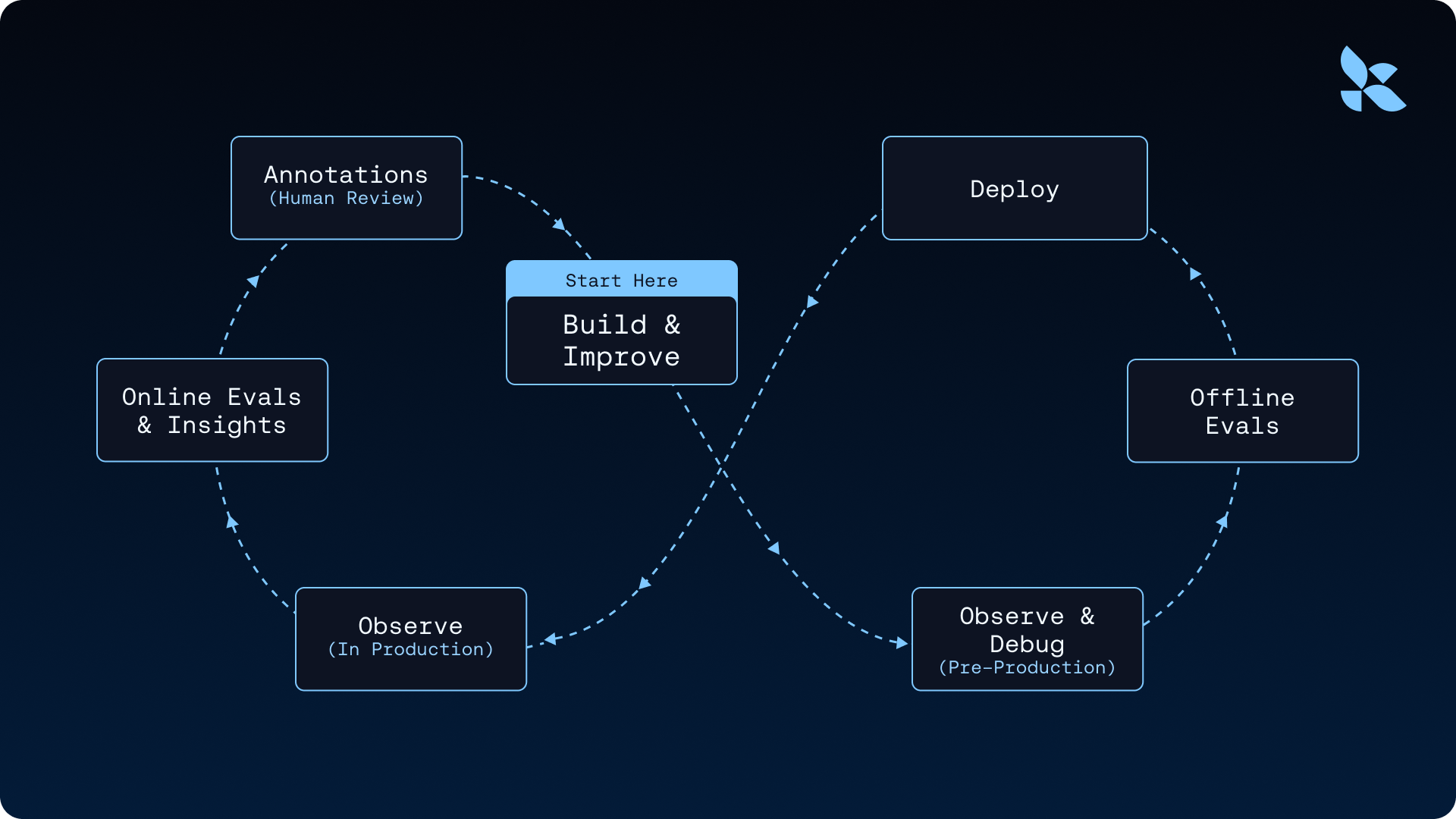
Observability and improvement loop¶
Production behavior is path-dependent; traces expose model choices, tool IO, subagents, and middleware. LangSmith Deployment is wired to tracing projects; Polly and online evals close the loop from traces to harness changes. The article cites harness-only improvements on Terminal Bench 2.0 as evidence for trace-driven iteration.
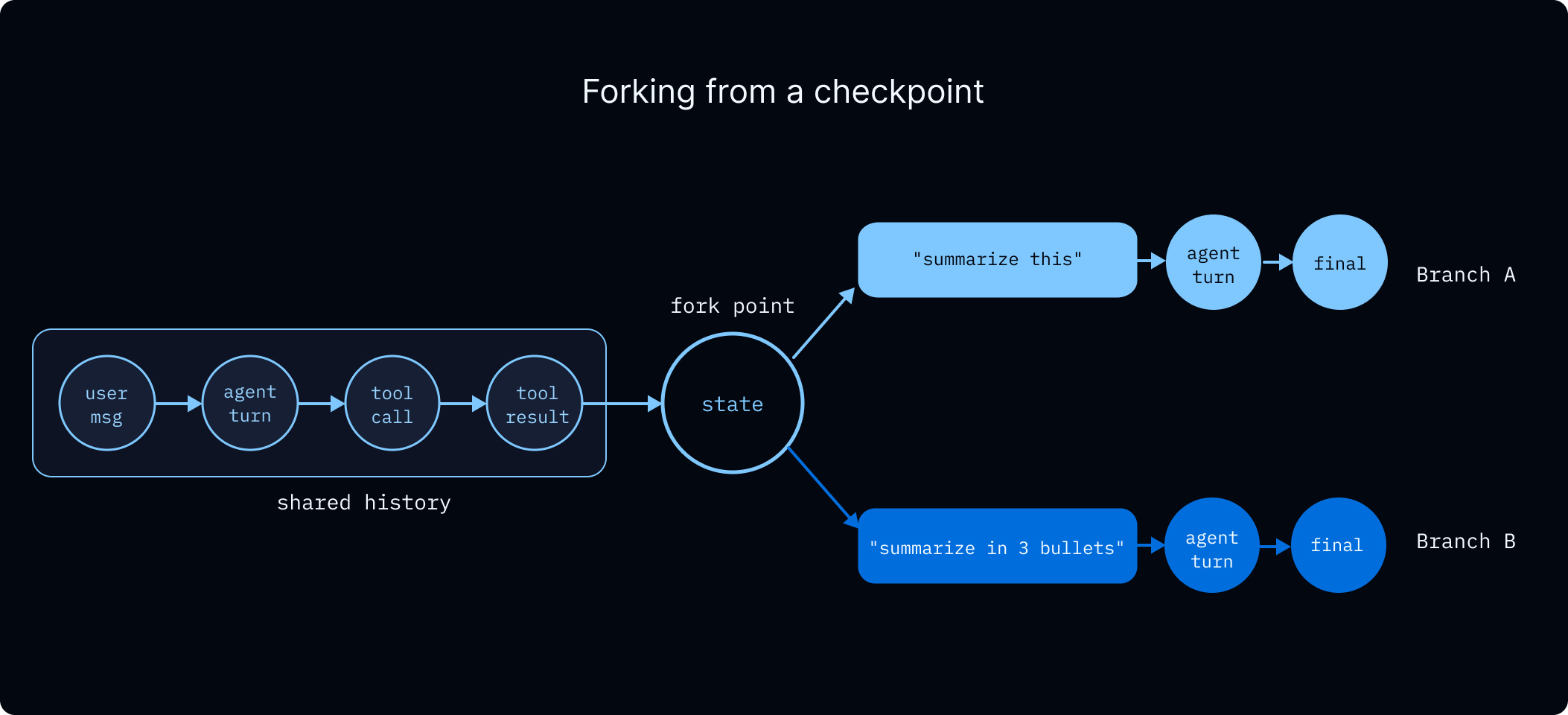
Time travel¶
Checkpoints make each super-step a rewind point: pick history, optionally mutate state, fork forward without destroying the original branch. Supports debugging wrong tool choice, prompt comparisons on identical upstream context, and recovery from bad trajectories. Studio UI and API are both mentioned.
Code execution (sandboxes)¶
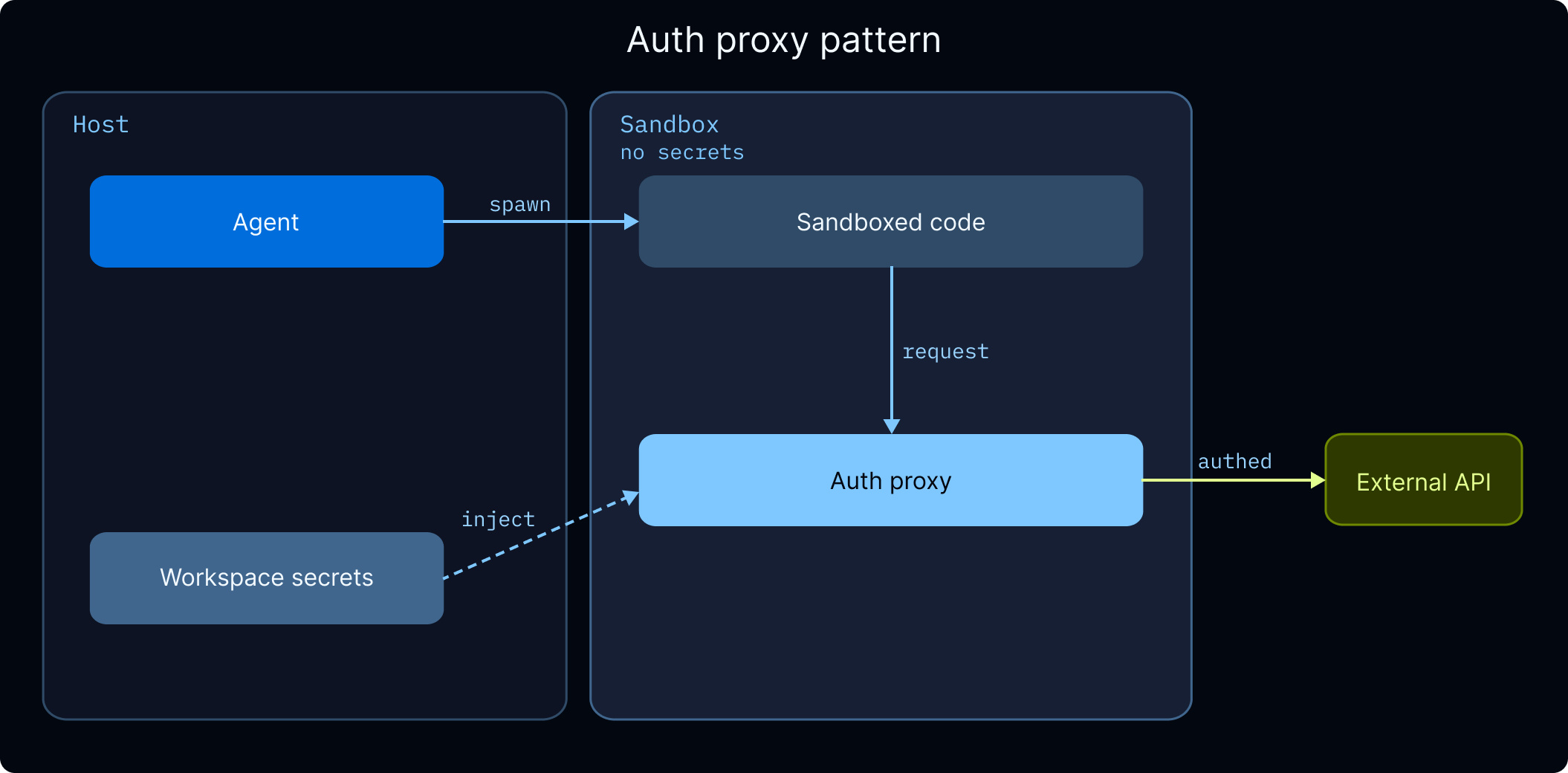
Pre-wired tools limit agents; arbitrary code needs sandbox backends implementing a sandbox protocol, exposing execute only when configured. Providers named include Daytona, Modal, Runloop, and LangSmith Sandboxes (preview at time of article), with templates, warm pools, and an auth proxy so secrets stay outside the sandbox. The article warns: sandboxes protect the host, not credentials placed inside the sandbox.
Integrations¶
- MCP : inbound MCP endpoint on deployments; outbound MCP to external tool servers.
- A2A : agent-to-agent discovery and calls across deployments.
- Webhooks : POST on run completion to chain downstream workflows with configurable security.
Cron and proactive agents¶
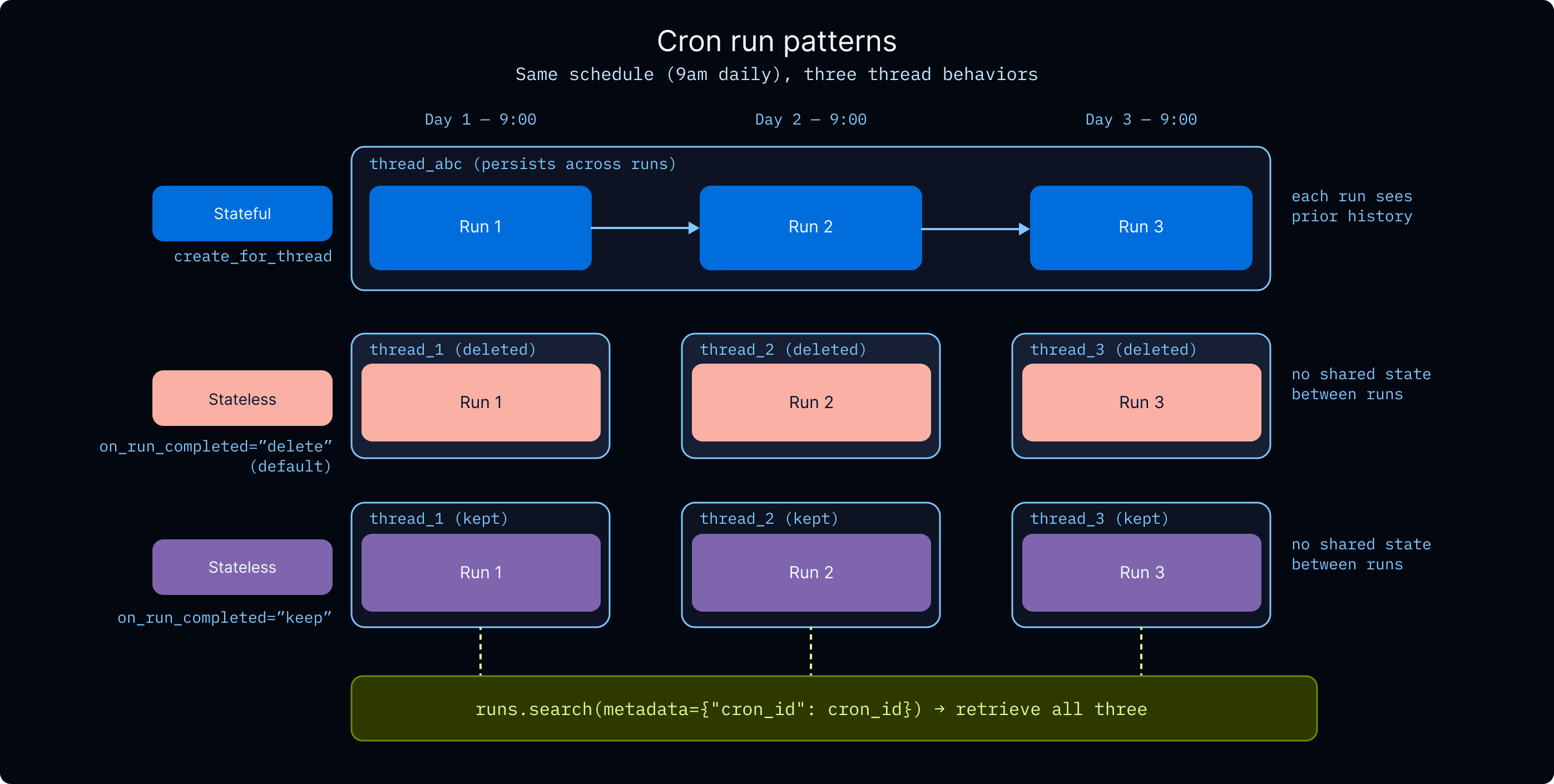
Reactive chat is only part of the story; scheduled sleep-time compute and health/monitoring loops need the same durability, tracing, and auth. Stateful cron appends to a fixed thread_id; stateless cron creates fresh threads with optional cleanup policies.
Deployments may be cloud, hybrid, or self-hosted with the same capability set per the article.
deepagents deploy and open harness¶
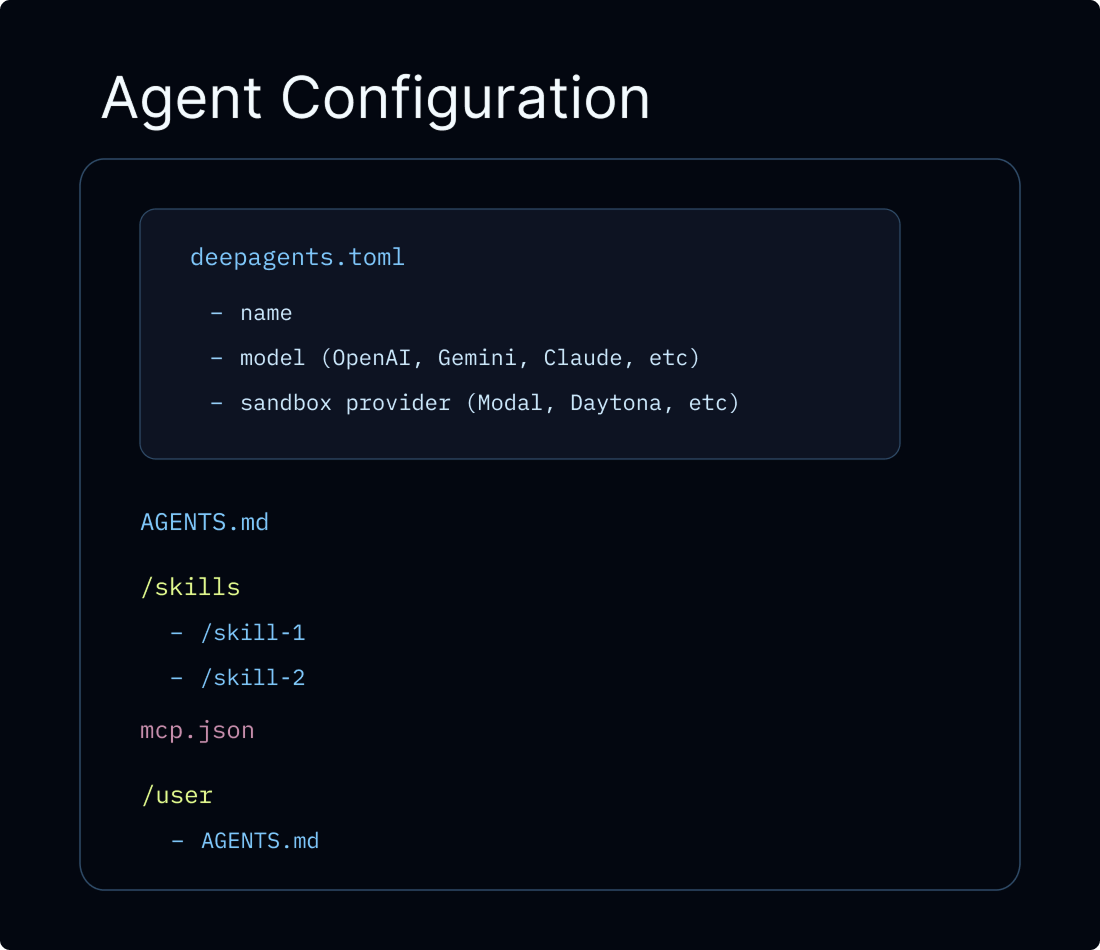
deepagents deploy packages agent config (deepagents.toml) onto the described runtime: virtual filesystem memory backends, sandbox provider selection, auto-detected skills/ and AGENTS.md, and mcp.json servers. The open harness section argues against opaque managed lock-in: MIT-licensed Deep Agents, open agent exposure protocols, and inspectable middleware for limits, retries, fallbacks, and PII handling.
Closing thesis¶
Production agents need durable execution, memory, tenancy, guardrails, HITL, observability, sandboxes, integrations, and schedules as infrastructure, not one-off app code. The article positions packaging (deepagents deploy) plus an improvement loop (traces -> evals -> harness changes) as the path from prototype to operable agents.